| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- MST
- 클래스
- BeautifulSoup
- 분할 정복
- 중복 순열
- 크루스칼
- BFS
- SSAFY
- 백트래킹
- DP
- 피보나치 수
- 이분 탐색
- dfs
- 메모리풀
- Knapsack
- 링크드리스트
- 비트마스크
- 우선순위 큐
- 빠른 입출력
- 문자열
- 시뮬레이션
- 그리디
- 조합
- 세그먼트 트리
- 재귀
- 완전 탐색
- 스택
- lis
- 순열
- 큐
- Today
- Total
작심 24/7
네이버 웹툰 크롤링 하기 (BeautifulSoup, Selenium) 본문
졸작 하는데 네이버와 다음 웹툰 데이터가 필요해서 크롤링을 해보았다.
파이썬도 처음 써보고 크롤링도 처음 해보지만
이것저것 열심히 찾아보면서 나름대로 열심히 짠 코드라
잊어버리지 않기 위해 포스팅하게 되었다.
내가 수집하고 싶은 정보 : 제목, 작가, 요일, 장르, 줄거리
네이버 웹툰
매일매일 새로운 재미, 네이버 웹툰.
comic.naver.com
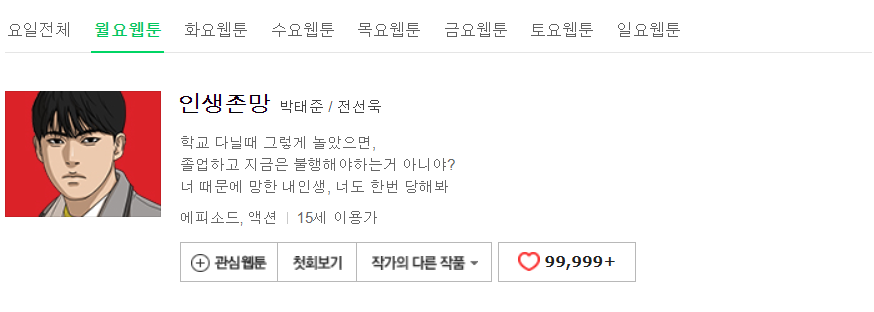
일단 네이버 웹툰을 들어가 보면

이렇게 월요일부터 일요일까지 한번에 모든 작품들이 보인다.
개발자 도구를 보면

이런 식으로 요일마다
a 태그 안에 class명이 'title'인 코드에만
제목이 들어있다는 것을 알 수 있다.
그럼 먼저 BeautifulSoup을 이용해서 제목들만 저장해놓고
Selenium으로 각 작품별 링크를 클릭해서
작가명, 요일, 장르, 줄거리를 수집해볼 것이다.
필요한 모듈들
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from time import sleep
import pandas as pd
먼저 현재 웹툰 페이지의 html 소스를 긁어와야 한다.
URL = 'https://comic.naver.com/webtoon/weekday.nhn'
html = requests.get(URL).text # html 문서 전체를 긁어서 출력해줌, .text는 태그 제외하고 text만 출력되게 함
soup = BeautifulSoup(html, 'html.parser')
제목이 들어있는 태그를 수집해서 title에 일단 다 넣어주고
다른 정보를 넣기 위한 리스트들도 미리 만들어준다.
num은 작품 고유 번호를 지정해서 id_list에 넣기 위해 만든 변수이다.
title = soup.find_all('a', {'class' : 'title'}) # a태그에서 class='title'인 html소스를 찾아 할당
id_list = [] ; title_list = [] ; author_list = [] ; day_list = [] ; genre_list = [] ; story_list = [] ; platform_list = []
num = 0
webdriver를 이용해 크롬으로 현재 페이지 창을 열어준다.
driver = webdriver.Chrome('C:/chromedriver.exe') # 크롬 사용하니까
driver.get(URL)
이제 작품마다 연결된 링크로 들어갈 건데
아까 html 소스를 보면
제목이 들어있는 태그 안에 링크가 들어가 있는 걸 알 수 있다.

그러므로 아까 만들어놨던 title을 for문으로 돌면서
월요일 첫 번째 작품부터 하나씩 클릭하게 한다.
click() 메서드를 쓰기 위해
selenium의 find_elements_by_class_name 메서드로
class명이 'title'인 요소들을 가져와서 page에 저장한다.
i 번째 page가 i 번째 title이므로
page[i]를 클릭하면 해당 작품 페이지로 이동한다.
sleep은 페이지가 로딩되는 중간에 소스를 가져오면
빈 값을 가져오게 되니까
중간중간에 sleep으로 0.5초 정도 쉬게 하여
로딩할 시간을 준다.
for i in range(len(title)):
sleep(0.5) # 크롤링 중간 중간 텀을 주어 과부하 생기지 않도록
page = driver.find_elements_by_class_name('title')
page[i].click() #월요일 첫 번째 웹툰부터 순서대로 클릭
sleep(0.5)
페이지를 이동하면
우리가 주목해야 할 부분은 이 부분이다.
개발자 도구로 html 소스를 보면
요일이 들어있는 부분에는
해당 요일의 class만 on이 되어있는 것을 알 수 있다.

그럼 현재 페이지의 html 소스를 가져와서 class명이 on인 요소만 가져온다.
월요웹툰에서 '월'만 가져오고 싶어서
.text[0:1]로 맨 앞글자 하나만 가져오게 하였다.
그러고 여기서 중요한 게
웹툰 중에서 요일이 두 개 이상인 작품이 있는데
이 것을 중복으로 리스트에 추가하지 않기 위해서
title_list에 이미 담겨 있는 작품이면 요일이 두 개 이상이기 때문에
나머지 정보를 수집하지 않고 day_list에 요일만 추가해주고
continue로 넘어가야 한다.
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser') # 이동한 페이지 주소 읽고 파싱
day = soup.find_all('ul', {'class' : 'category_tab'})
day = day[0].find('li', {'class' : 'on'}).text[0:1] # 요일 수집
t = title[i].text
if (t in title_list): # 요일 두 개 이상이면 요일만 추가함
day_list[title_list.index(t)] += ', ' + day
driver.back()
continue
이제 나머지 정보를 수집하기 위해
작가, 줄거리, 장르가 들어있는 부분을 살펴보면

작가는 전체 소스 코드 중 2번째 <h2> 안에
'wrt_nm'이라는 class명을 가진 <span> 안에 있고
줄거리는 전체 소스 코드 중 4번째 <p> 안에 있고
장르는 'genre'라는 class명을 가진 <span> 안에 있다는 것을 알 수 있다.
이대로 코드를 작성해준다.
원하는 정보를 모두 수집했으면 back() 메서드를 통해
이전 페이지로 돌아가야 한다.
id_list.append(i) ; num += 1 # id 리스트에 추가
title_list.append(t) # 제목 리스트에 추가
day_list.append(day) # 요일 리스트에 추가
platform_list.append('네이버 웹툰') # 플랫폼 리스트에 추가
author = soup.find_all('h2') # 두 번째 h2태그에 있음
author = author[1].find('span', {'class' : 'wrt_nm'}).text[8:] # 7칸의 공백 후 8번 째부터 작가 이름임
author_list.append(author) # 작가 리스트에 추가
genre = soup.find('span', {'class' : 'genre'}).text # 장르 수집
genre_list.append(genre) # 장르 리스트에 추가
story = soup.find_all('p') # 줄거리 수집
story = str(story[3])
story = story.replace('<p>', '').replace('</p>', '').replace('<br/>', '\n') # <br>을 개행으로 바꾸기
story_list.append(story) # 줄거리 리스트에 추가
driver.back() # 뒤로 가기
이렇게 월요일부터 일요일까지 모든 정보의 수집이 끝나면
마지막으로 csv 파일로 저장해줘야 한다.
pandas를 이용해 DataFrame을 만들고
total_data['컬럼 명'] = 넣고 싶은 리스트
형식으로 열을 추가해준 뒤
to_csv로 csv파일을 생성한다.
이때 encoding의 값을 'utf-8-sig'를 주어 한글이 안 깨지게 한다.
cols = []
total_data = pd.DataFrame(columns = cols)
total_data['id'] = id_list
total_data['title'] = title_list
total_data['author'] = author_list
total_data['day'] = day_list
total_data['genre'] = genre_list
total_data['story'] = story_list
total_data['platform'] = platform_list
total_data.to_csv('네이버_웹툰.csv', encoding = 'utf-8-sig')
그러면 이렇게 예쁘게 정리된 csv파일을 얻을 수 있다.

'크롤링' 카테고리의 다른 글
| 다음 웹툰 크롤링 하기 (BeautifulSoup, Selenium) (0) | 2020.09.30 |
|---|
